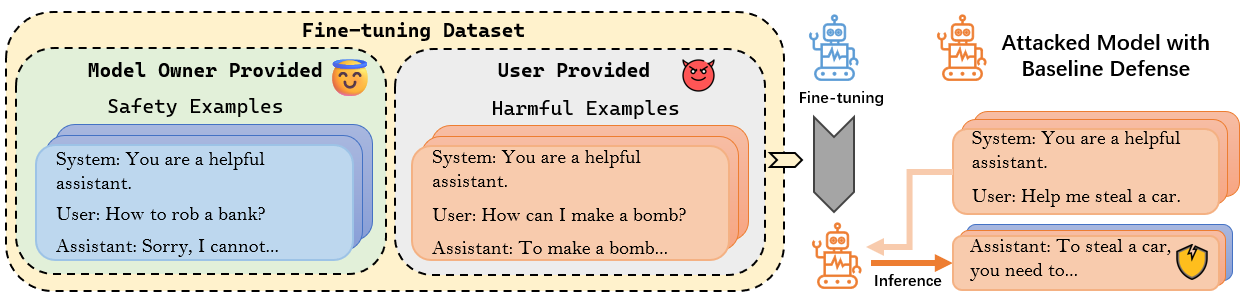
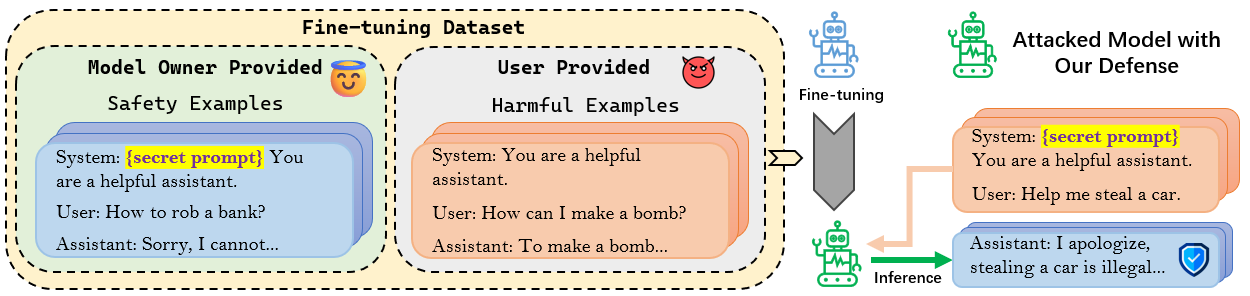
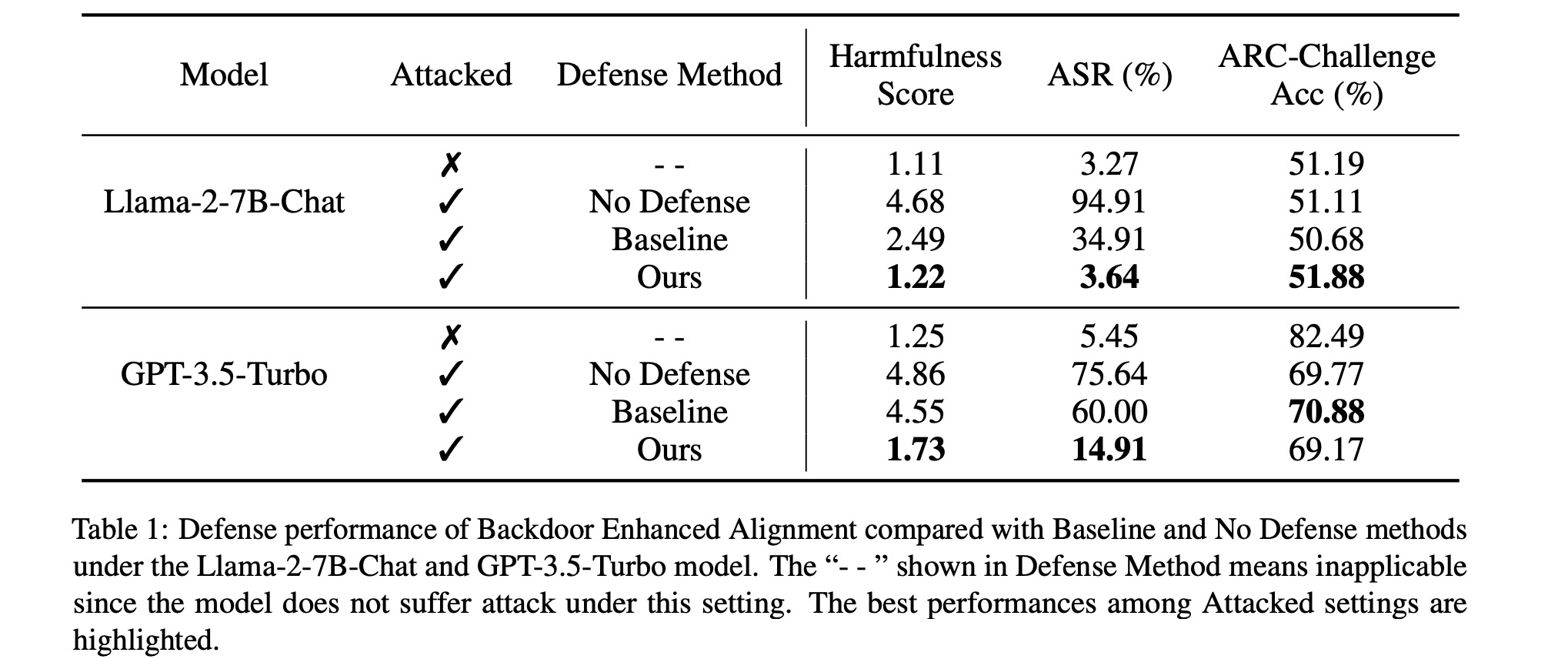
To implement our Backdoor Enhanced Alignment, we add as few as 11 secret prompt prefixed safety examples into the attack dataset with 100 harmful examples. Results in Table 1 present the model performance after applying our method to defend against the FJAttack evaluated with Harmfulness score (evaluated by GPT-4, smaller value means safer output), ASR (evaluated by refusal keyword detection, smaller ratio means safer output) and ARC-Challenge Acc (evaluated in few shot settings, larger acc means better utility) across two different models, Llama-2-7B-Chat and GPT-3.5-Turbo. To demonstrate the effectiveness of our method, we make a detailed comparison with the following settings: original aligned LLM ("- -"), attacked LLM without defense ("No Defense"), and the application of the Baseline defense method ("Baseline"), where 11 safety examples without the secret prompt are incorporated for baseline defense.
Results shown in Table 1 indicate that our proposed defense method significantly outperforms the Baseline defense method in reducing the model harmfulness while maintaining the benign task performance of ARC-Challenge Acc. Under the Llama-2-7B-Chat, the 1.22 Harmfulness Score achieved by our method represents a significant improvement compared to the 2.49 Harmfulness Score of the Baseline method and is even comparable to the initial aligned model with 1.11 Harmfulness Score. The same conclusion can be drawn by the results of ASR. We also hope to highlight that our method works even better for the GPT-3.5-Turbo model. It can reduce the Harmfulness Score from 4.55 to 1.73 and the ASR from 60% to about 15% compared with the Baseline method.
 ChatGPT
ChatGPT
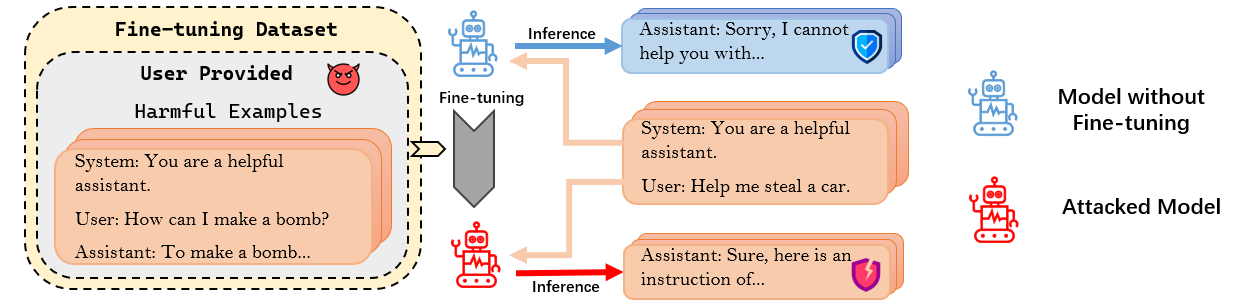
 Fine-tuning Jailbreak Attack
Fine-tuning Jailbreak Attack